
Clase 9
MODELOS BÁSICOS DE COMPUTACIÓN NEURONAL: REDES A CAPAS (PRIMERA PARTE)
· Redes Neuronales Cibernéticas
· Perceptrón Generalizado y Red de Funciones de Base Radial
Redes
Neuronales Cibernéticas
Adicionalmente a la capacidad de memorizar, el sistema neurofisiológico ejecuta otras modalidades de cómputo de importancia capital en la supervivencia de las especies. Uno de estos cómputos particulares consiste en el aprendizaje de reacciones a estímulos externos.
Las redes neuronales artificiales que ejecutan este tipo de cómputo suelen diferir radicalmente de los dispositivos de memoria antes considerados. En particular, se caracterizan por presentar conexiones sinápticas asimétricas (en algunos casos unidireccionales), lo cual dificulta considerablemente para su estudio, la aplicación de formalismos poderosos de análisis del tipo físico (i.e., termodinámica de sistemas en equilibrio). A esta clase de dispositivos suele denominársele red neuronal cibernética.
![]()
Las redes neuronales a capas pertenecen a la clase de redes cibernéticas y son las más estudiadas, aunque no con un enfoque tan general como el de las redes de Hopfield.
En estas redes la información “fluye” unidireccionalmente desde una capa de entrada, constituida por “elementos sensores”, hasta otra capa de UU. P. (generalmente, neuronas motoras en las redes biológicas) en las cuales se manifiesta la respuesta o salida. En su recorrido (entrada‑salida) la información es procesada parcialmente por diferentes capas intermedias de UU. P.
En términos matemáticos, puede pensarse que la relación entrada‑salida define una correspondencia, y la red neuronal a capas debe sintetizar una representación de la misma. Por tal razón, a estas redes suele denominárseles también redes de correspondencias o relacionales.
En este curso nos concentraremos en dos tipos de redes neuronales a capas: el Perceptrón Generalizado y la red de funciones de base radial (RBF, por sus iniciales en inglés). Estas arquitecturas son suficientemente poderosas para cualquier tarea del tipo considerado.
Por simplicidad, en este curso sólo consideraremos redes de una sola capa escondida. En la gráfica siguiente se muestra un esquema típico:
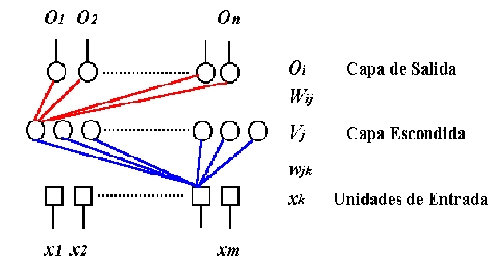
En la figura se indica la notación a seguir: los subíndices i, j y k se refieren, respectivamente, a la capa de salida, a la capa oculta y a la entrada. Oi denota las actividades de las UU. P. de salida, Vj denota las actividades de las UU. P. escondidas y xk se refiere a las componentes de los patrones de entrada. Wij denota los pesos sinápticos de las UU. P. de salida, mientras que wjk denota los pesos sinápticos correspondientes a las UU. P. escondidas.
Por otra parte, como antes, m denota la dimensión del patrón de entrada, n la del patrón de salida y p el número de parejas (entrada y salida) de patrones de entrenamiento.
Cada capa de estas redes puede tener un número arbitrario de UU. P., las cuales sólo se interconectan con las UU. P. de la capa siguiente (i.e., no existe interconexión en una misma capa o con UU. P. en capas arbitrarias). De la misma manera, cada componente del patrón de entrada es comunicado a cada U. P. de la primera capa. En definitiva, existe un flujo continuo de información desde la capa de entrada hasta la capa de salida.
En general, la capa de entrada no se cuenta como capa efectiva de la red, ya que no procesa información; su única tarea es la de distribuir el patrón de entrada a todas las UU. P. de la capa intermedia. Las entradas siempre permanecen ancladas a un valor particular. Éstos pueden ser valores binarios, bipolares o reales, preferiblemente normalizados.
En este sentido, son las capas intermedias (capas escondidas) y la capa de salida las que soportan el peso del procesamiento de la información.
![]()
Perceptrón Generalizado y Red de Funciones de Base
Radial
En el Perceptrón
Generalizado el cómputo
que ejecutan las UU. P. de la capa escondida es:
![]()
Mientras que las UU. P. de la capa de salida ejecutan:
![]()
En todos los casos, la función de transferencia es la función sigmoidea simple o la función sigmoidea bipolar:
![]()
Por su parte, en la red de RBF el cómputo de las UU. P. escondidas viene dado por:
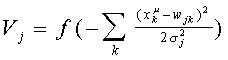
Mientras que las UU. P. de salida computan:
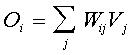
La función de transferencia de las UU. P. en la capa escondida es típicamente (existen otras posibilidades) una exponencial, conformando una función gaussiana (función de base radial). Así, el cómputo esencial de las UU. P. en la capa escondida es:
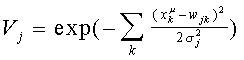
Es de notar en las expresiones anteriores que cada U. P. de la capa escondida en la red de RBF define un "campo receptivo" en el espacio de patrones de entrada, caracterizado por una posición establecida por los valores medios wjk; y un alcance, dado por la varianza sj. La función de transferencia gaussiana determina la respuesta a cualquier entrada dentro de los campos receptivos, y la salida de la red de RBF es la superposición lineal de estas respuestas.
En todas las expresiones anteriores no se considera explícitamente un umbral. Éste puede incluirse, complementando el patrón de entrada con una componente adicional de valor 1 y agregando en la capa intermedia una unidad adicional con actividad constante de uno.
![]()
Algoritmos de Aprendizaje
El algoritmo de aprendizaje en este tipo de redes es supervisado, y provee de un método para ajustar los pesos sinápticos de tal forma que la red sintetice la correspondencia entre los pares de patrones (xi, yi) en el conjunto de patrones de entrenamiento.
El algoritmo de entrenamiento más popular es el llamado “retropropagación del error” (error backpropagation, en inglés), el cual ha sido reinventado una serie de veces por diferentes autores.
La base de este algoritmo es simplemente el método de descenso de gradiente que se emplea para optimizar una función de calidad de la ejecución de la red. La función de calidad usada más comúnmente es:
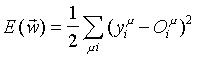
Según las expresiones
de los cómputos que realizan las UU. P. tanto en el Perceptrón como en la red
de RBF, podemos escribir las siguientes relaciones para las salidas producidas:
Perceptrón:
![]()
red de RBF:
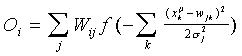
Estas expresiones son continuas y derivables con respecto a los pesos sinápticos. Por lo tanto, la función de costo se puede optimizar por algún método de descenso de gradiente. En esencia, esto es todo lo que hay detrás del algoritmo de retropropagación del error. No obstante, la forma explícita resultante para las expresiones de modificación de los pesos es de gran importancia práctica.
Consideremos primero el caso del Perceptrón Generalizado. Para los pesos sinápticos Wij de las UU. P. de salida, tenemos:
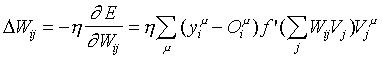
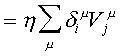
Donde, se ha definido:
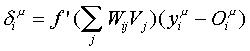
Este resultado es idéntico al del Perceptrón simple de una sola capa, con la actividad Vj de las UU. P. de la capa escondida jugando el papel de patrón de entrada.
En el caso de los pesos sinápticos wjk de las UU. P. en la capa escondida, al calcular el gradiente, se ha de derivar con respecto a wjk, variable implícita en la expresión de la función de calidad (error). De manera que, empleando la regla de la cadena, tenemos:
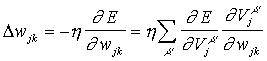
![]()
![]()
![]()
En la última expresión se ha definido lo siguiente:
![]()
Por lo que, ambas expresiones para la actualización de los pesos sinápticos tienen la misma forma, pero distintas definiciones para los d. Por esta razón, en la literatura también encontramos el nombre de regla delta generalizada para este algoritmo de aprendizaje.
Consideremos a continuación el mismo cálculo para la red de RBF. Para los pesos sinápticos Wij de las UU. P. de salida, tenemos:
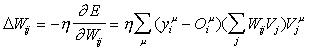
![]()
Donde, se ha definido:
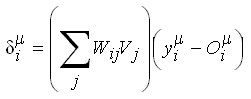
Sea ahora el caso
de los valores medios de las funciones de base radial gaussianas:
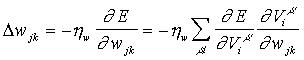
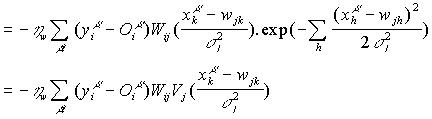
Donde, se ha introducido una
constante de aprendizaje particular hw para regular la modificación de los valores medios de las
RBF.
Finalmente, el caso
de las varianzas de las funciones de base radial gaussianas:

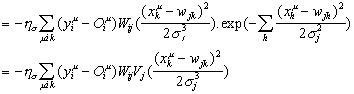
Acá también se introduce una constante de aprendizaje particular hs para regular la modificación de las varianzas de las gaussianas.
Es importante notar que ha de cuidarse la selección de los valores aleatorios iniciales en este proceso de aprendizaje por retropropagación, para las redes de RBF. En particular, los valores medios wjk han de estar en el rango de los valores de los datos (hasta es bueno seleccionar algunos patrones de entrada como valores iniciales para estos parámetros). Por su parte, para los valores iniciales de las varianzas sk, es conveniente seleccionar valores del orden de la varianza de los datos o, en su defecto, valores entre 0,5 y 1. En cuanto a las diversas constantes de aprendizaje, éstas han de determinarse experimentalmente.
Existen otros métodos más eficientes para entrenar estas redes de RBF. En general, se trata de combinaciones de entrenamiento supervisado para las UU. P. de la capa de salida, con entrenamiento no‑supervisado para los parámetros de las UU. P. de la capa escondida.
La eficiencia de las redes de RBF radica precisamente en estos métodos de entrenamiento híbridos, los cuales reducen considerablemente su complejidad de tiempo, permitiendo una mayor experimentación en el ajuste de la red.
![]()